


https://elchapuzasinformatico.com/wp-content/uploads/2020/06/FIFA-21.jpg
A hands-on guide to cleaning the Fifa 2021 dataset.
Introduction
I decided to participate in #DataCleaningChallenge on the dataset provided using Pandas to try out my data cleaning skills and improve my data cleaning skills. This #datachallenge was organized by Promise Chinonso to provide an avenue for Data Analysts to meet with fellow learners and build a great network.

Data in its raw form is poorly structured and challenging to work with. It could contain errors, inconsistencies, missing values, Duplicate entries, Mislables, and other flaws that make analysis or other use difficult. As a result, data must be processed and cleansed before it can be used appropriately.
Data cleaning is detecting and correcting data flaws such as misspellings, duplicate entries, or wrong data types. Data processing entails changing data into a more acceptable format for analysis.
By cleaning and processing, we can increase the quality of data and make it more usable for decision-making, research, and other uses. It is an essential step in the data analysis process which is why data analysts spend 80% of their time on cleaning data.
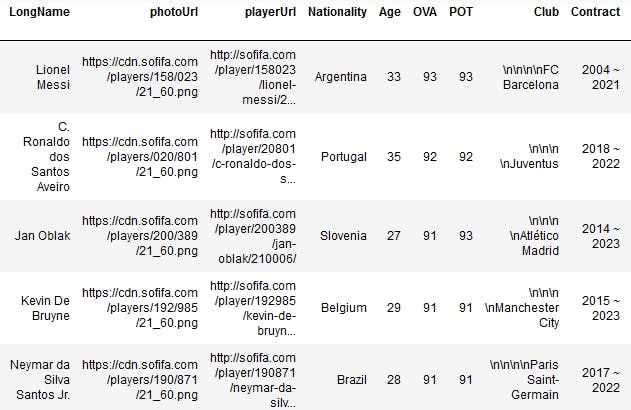
About the Data.
The Fifa21 dataset was used for this data-cleaning challenge. You can download the dataset from Kaggle. to participate in this challenge.
Data Cleaning Processes
Before we proceed with our cleaning, we have to import the libraries needed for this process. Pandas library is the ultimate library used for this process. The next step would be to import our FIFA21 dataset and ensure we can load the data by inspecting the first 5 rows of the data.
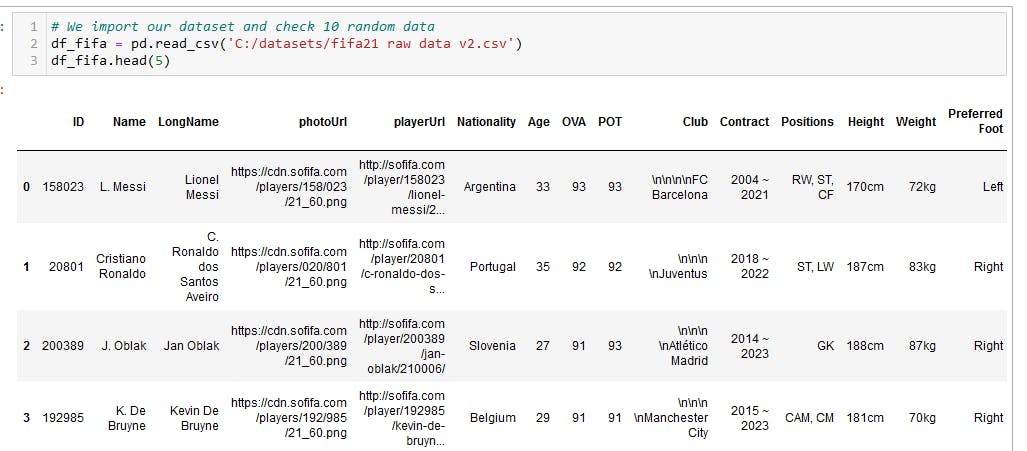
Data Inspection
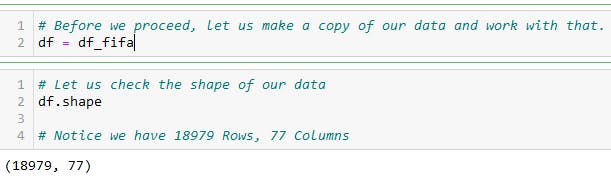
Data inspection is the process of analyzing the data to find any potential flaws or inconsistencies that could affect the accuracy of the data. The first thing before inspecting my data is usually to create a copy of the data and work with the copied data.
Check for Missing Values and Duplicates
To check for missing values, the .isnull() method is used.
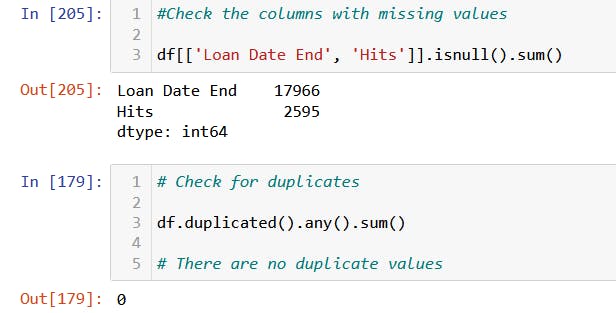
Notice the number of missing values in 'Loan Date End' 17966. I decided to drop it, but there are other means of handling missing values(fill with 0, mean, median, mode, forward fill, backwards fill, etc.).

Rename features in the dataset
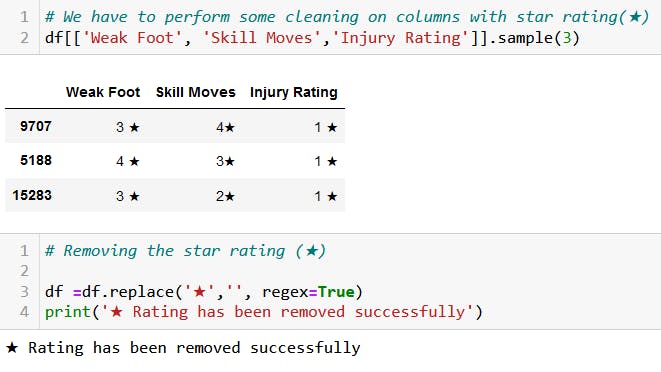
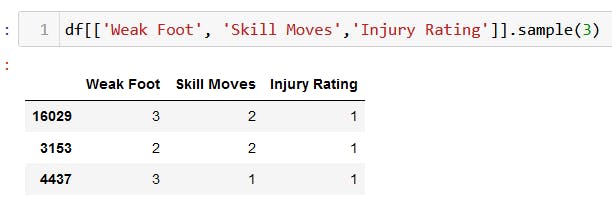
The ★ has been removed from the following columns 'Weak Foot', 'Skill Moves', and' Injury Rating'.
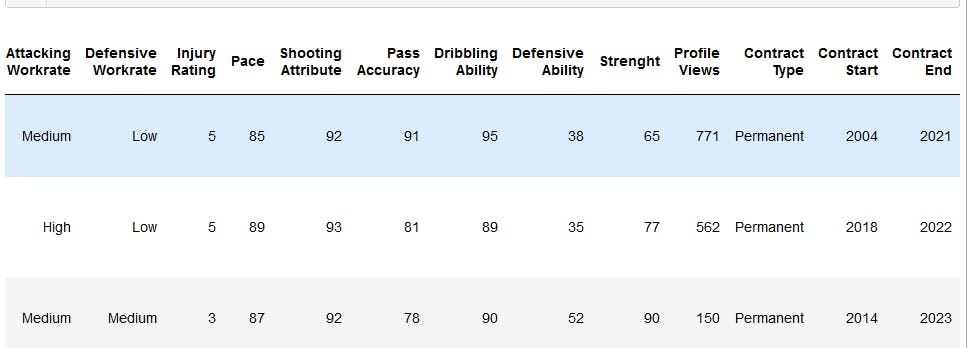
This is what the data looks like after cleaning.
Saving Data
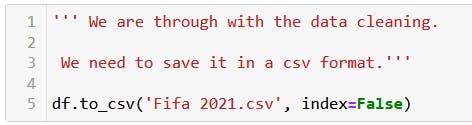
Once data cleaning is complete, the next step is to save your cleaned data.
Conclusion
This challenge is focused on data cleaning and preparing data for analysis. The data cleaning process successfully identified and resolved issues such as missing values, wrong data types, mislabels, drop irrelevant columns, and improper data entry. The data cleaning step is iterative and we need to be double-sure before concluding that our dataset is clean and free of specks of dirt.