Data in its natural form is unclean(missing values, improper data entry, and mislabels) and as a data scientist, you have to clean data by removing noise and outliers from the data before deriving concepts from the data. It is often said that data scientists spend 80% of their time cleaning and preparing data and the remaining 20% is spent on visualization.
Let's use the analogy of a fish to drive home our point. Just as removing bones from fish requires carefulness, data cleaning requires careful attention to identify and address inaccuracies and inconsistencies in the data. Data cleaning is therefore the process of identifying and handling errors, and inconsistent and missing values in our dataset so that it can be used for effective data analysis.
To see and understand what data cleaning entails, let's dive into our Jupyter notebook and import our dataset.
Step 1: Load the necessary library and import our dataset into pandas DataFrame.

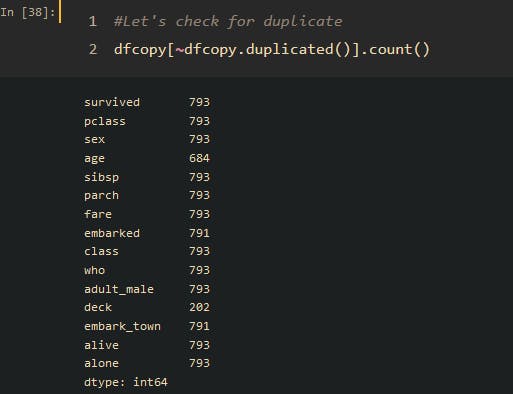
Step 2: Check for duplicates
Next, we have to remove duplicates but before we proceed, it is always best practice to make a copy of our data and perform our cleaning on the copy.
dfcopy[~dfcopy.duplicated()].count()
The duplicates will be dropped keeping only the first entry of those duplicate values. dfcopy.drop_duplicates(keep='first' , inplace=True)
Step 3 Check for Missing values
After successfully removing the duplicated data, we can now proceed to check for missing values using df.isna().values.any()

Step 4 Treat for Missing values
There are several methods to fill in missing values( NA, NaN); Mean/Median/Mode Imputation but for the sake of this analysis, we would use the interpolation method to fill in missing values(NA).
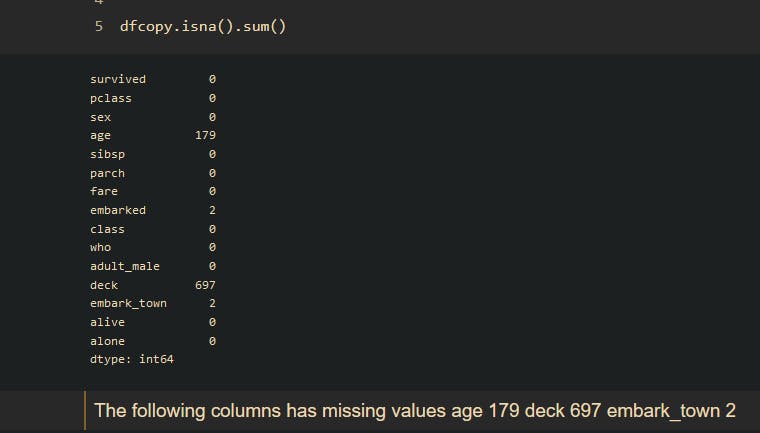
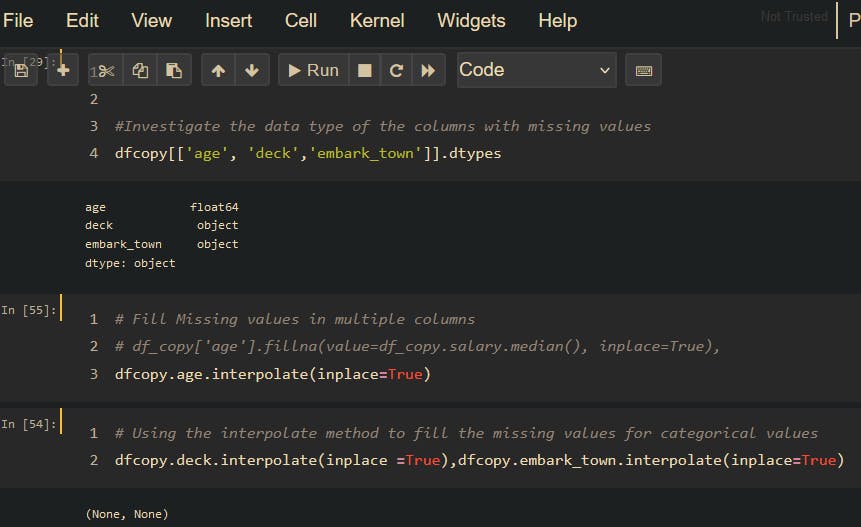
Now that we have successfully filled in the missing values, let's check if there are still missing values using this code dfcopy.isna().sum()
survived 0
pclass 0
sex 0
age 0
sibsp 0
parch 0
fare 0
embarked 0
class 0
who 0
adult_male 0
deck 0
embark_town 0
alive 0
alone 0
dtype: int64
There are no missing values but the dfcopy['age'] is in float and age is not written as 33.8 so therefore, we will write a function to select the floor(33.8 = 33) of the age feature.

Step 5 Check for the unique data entries.
Data types: dfcopy.sex.unique()
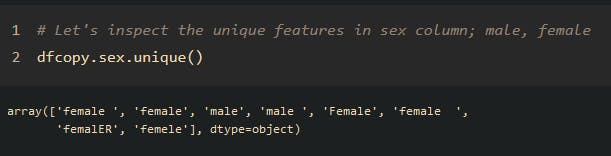
Now you see the essence of inspecting our data thoroughly for improper data entry sex is supposed to capture male or female gender.
array(['female ', 'female', 'male', 'male ', 'Female', 'female ',
'femalER', 'femele'], dtype=object)
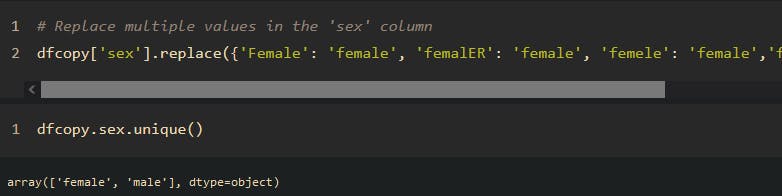
dfcopy['sex'].replace({'female ': 'female', 'male ':'male', 'female ':'female'},inplace=True)
Now we are left with clean data which we will export to a comma-separated value (CSV) format. This can be done using the to_csv method in Pandas.
dfclean= dfcopy.to_csv('titanic_clean.csv', index=False)